Tipos de Replicação no SQL Server – Visão Geral
 Tempo de leitura: 6 minutos
Tempo de leitura: 6 minutosOlá pessoal,
Espero que estejam todos bem!
A replicação é um assunto extenso e tem suas particularidades, então vou tentar explicar de forma clara e prática para que vocês possam entender quando usar cada tipo.
O que é a Replicação no SQL Server?
Basicamente, você tem dados em um local e precisa que esses mesmos dados estejam disponíveis em outro local, mantendo tudo sincronizado. Simples assim!
O SQL Server oferece quatro tipos principais de replicação:
- Transacional;
- Snapshot;
- Merge;
- Peer to Peer (não vamos abordar esse tipo neste artigo);
Saiba mais na documentação oficial
Cada tipo tem suas características específicas e casos de uso ideais. Vamos entender cada um deles.
Antes de mergulharmos nos tipos, é importante entendermos alguns conceitos básicos que vamos usar durante todo o artigo.
Replicação Transacional
A replicação transacional copia os dados de maneira unidirecional do banco de dados de origem para o banco de dados de destino. Ela usa os arquivos de log do banco de dados de origem (LDF) para manter os dados em sincronia com o assinante.
É o tipo mais comum e usado na maioria dos cenários corporativos.
Replicação Snapshot
Ideal para dados que não mudam com frequência ou quando você precisa de atualizações completas periódicas.
Replicação Merge
A replicação merge permite que dois ou mais bancos de dados sejam mantidos em sincronia. Sempre que as alterações ocorrem em um banco de dados (se configurado para isso), elas serão automaticamente refletidas aos outros bancos de dados de maneira bi-direcional. Se as alterações ocorrerem no Publicador, elas serão aplicadas ao Assinante e vice-versa.
É mais complexa de configurar e gerenciar, mas oferece flexibilidade para cenários onde você precisa de atualizações bidirecionais.
Matriz de Compatibilidade
Topologia da Replicação
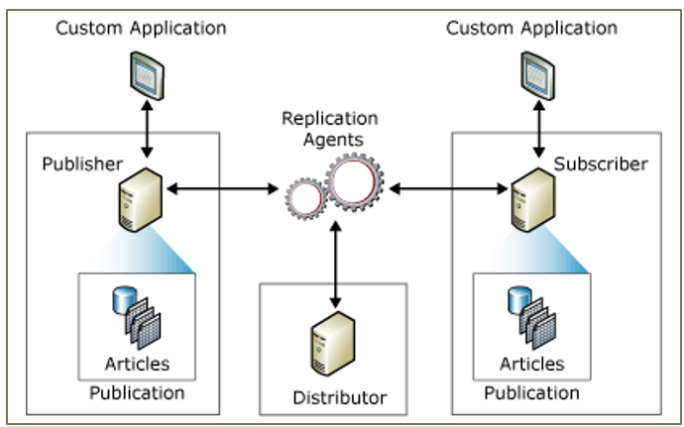
- Custom Application (sua aplicação)
- Publisher (servidor que publica os dados)
- Replication Agents (agentes que fazem o trabalho)
- Distributor (servidor que distribui as mudanças)
- Subscriber (servidor que recebe os dados)
- Articles Publication (objetos que são replicados)
Saiba mais na documentação oficial
Entidades de Replicação – Origem
Vamos entender os componentes do lado da origem:
- Publisher (Publicador): É um banco de dados de origem no qual a replicação é iniciada. Disponibiliza dados para replicação. Os publicadores definem o que publicam por meio de uma publicação.
- Article (Artigo): Os artigos são os objetos de banco de dados reais incluídos na replicação, como tabelas, views, índices, etc. Um artigo pode ser filtrado quando enviado ao assinante.
- Publication (Publicação): Um grupo de artigos é chamado de publicação. Um artigo não pode ser distribuído individualmente. Portanto, a publicação é necessária.
- Distributor (Distribuidor): É o intermediador entre editor e assinante. Ele é quem recebe transações ou snapshots publicados e, em seguida, armazena e encaminha essas publicações para o assinante.
Entidades de Replicação – Destino
Do lado do destino temos:
- Subscriber (Assinante): É o banco de dados de destino onde a replicação termina. Pode inscrever-se em várias publicações de vários publicadores. Ele pode enviar dados de volta ao editor ou publicar dados para outros assinantes.
- Subscription (Inscrição): É uma solicitação de um assinante para receber uma publicação. Nós temos dois tipos de assinaturas: push e pull.
- Push Subscription (Empurrar a subscrição): Com uma assinatura push, o Publicador propaga alterações para um Assinante sem uma solicitação do Assinante.
- Pull Subscription (Puxar a subscrição): Com uma assinatura pull, o Assinante solicita alterações feitas no Publicador. As assinaturas pull permitem que o usuário no Assinante determine quando as alterações de dados são sincronizadas.
Comparações entre os Tipos de Replicação
Vou fazer uma comparação prática entre os três tipos principais:
- Funciona em qual recovery model? Todos.
- Quem aplica o snapshot? Distribution Agent.
- As tabelas necessitam de PK? Sim.
- A replicação afeta o tamanho do Log de transações? Sim.
- Índices criados/excluídos são replicados nativamente? Não.
Snapshot:
- Funciona em qual recovery model? Todos.
- Quem aplica o snapshot? Distribution Agent.
- As tabelas necessitam de PK? Não.
- A replicação afeta o tamanho do Log de transações? Não.
- Índices criados/excluídos são replicados nativamente? Não.
Merge:
- Funciona em qual recovery model? Todos.
- Quem aplica o snapshot? Merge Agent.
- As tabelas necessitam de PK? Não.
- A replicação afeta o tamanho do Log de transações? Não.
- Índices criados/excluídos são replicados nativamente? Não.
- Requer a Feature SQL Server Replication previamente instalada nos ambientes (Origem e Destino).
- Caso queira configurar a replicação em dois servidores distintos, eles precisam se comunicar.
- Caso queira configurar a replicação em dois servidores distintos como PULL, é necessário ter uma pasta compartilhada com acesso de ambos os servidores.
Vantagens:
- A replicação transacional pode ser usada como um servidor de Relatórios.
- Ela pode replicar os dados de um servidor para o outro com baixa latência.
- A replicação transacional pode ser implementada a nível de objeto do banco de dados, como no nível da tabela.
- A replicação transacional pode ser usada para outros usos gerais, como atualizar dados sem executar o processo em seu principal (caso ele estiver ocupado).
- Pode ser propagado para um ou mais assinantes.
Desvantagens:
- Não é uma cópia fidedigna do banco de dados, portanto, não deve ser utilizada como DR.
- Dependendo do volume de transações o seu arquivo de T-LOG pode ficar retido até finalizar a carga e crescer exponencialmente, isso pode ser visto na tabela sys.databases coluna log_reuse_wait_desc (REPLICATION).
- Locks ocorrem no publicador (servidor de origem) nas primeiras etapas de geração do arquivo de snapshot.
- As peças de Backup tendem a ficarem maiores.
Vantagens e Desvantagens da Replicação Snapshot
Vantagens:
- Simplicidade e confiabilidade no processo de configuração.
- Ideal para replicar dados estáticos ou que mudam lentamente.
- É considerada uma feature simples de instalar e fácil de manter.
- Pode ser propagado para um ou mais assinantes.
Desvantagens:
- Uma das principais desvantagens é o alto consumo de recursos e largura de banda da rede.
- Transfere todo o conjunto de dados todas as vezes, independente se houveram alterações na origem ou não.
- Locks ocorrem no publicador (servidor de origem) nas primeiras etapas de geração do arquivo de snapshot.
- Pode gerar bastante latência e inconsistência de dados, pois o banco de dados de destino pode não refletir as alterações mais recentes feitas nos dados de origem até que o próximo snapshot seja obtido.
Vantagens e Desvantagens da Replicação Merge
Vantagens:
- Permite que os assinantes atualizem os registros de maneira independente
- Trabalha offline
- Dados sincronizados de maneira bilateral
- Pode ser propagado para um ou mais assinantes
Desvantagens:
- Configurar a replicação merge pode ser uma tarefa complexa e desafiadora
- É um cenário propenso a criar conflitos entre publicador e assinante, exigindo que os usuários resolvam com frequência os problemas
- Locks ocorrem no publicador (servidor de origem) nas primeiras etapas de geração do arquivo de snapshot
- Exige muito cuidado na manutenção, pois, caso seja necessário recriar a subscrição os dados que ainda não foram sincronizados pelo assinante podem ser perdidos
A escolha do tipo de replicação depende muito do seu cenário específico. A replicação transacional é a mais comum e atende a maioria dos casos. A snapshot é boa para dados que mudam pouco. Já a merge é para casos específicos onde você precisa de sincronização bidirecional.
Se tiverem dúvidas ou quiserem compartilhar experiências com replicação, deixem nos comentários! A troca de conhecimento sempre enriquece todos nós.
Um grande abraço a todos, até a próxima!
Gustavo Larocca





